
Un guide complet sur les données de nuages de points LiDAR 3D
8 août 2024

Dans les années 1960, Maiman et Lamb du Hughes Lab ont été les pionniers du premier laser au monde, un laser ruby émettant de la lumière rouge à 694,3 nm. À mesure que la technologie laser a progressé, LiDAR (Light Detection and Ranging) a également évolué, utilisant des lasers pour la détection.
Au départ, LiDAR était principalement utilisé dans la recherche scientifique, comme la détection météorologique et la cartographie topographique des océans et des forêts.
Dans les années 1980, avec l'introduction de structures de numérisation, le champ de vision de LiDAR s'est élargi, trouvant des applications dans des domaines commerciaux comme la conduite autonome, la perception environnementale et la modélisation 3D, devenant une technologie clé dans ces domaines.
Qu'est-ce que LiDAR ?
Définition et caractéristiques de LiDAR
LiDAR (Light Detection And Ranging) est un système de détection actif qui utilise des lasers comme source d'émission. Il mesure la position, la vitesse et la forme des cibles en émettant des faisceaux laser et en recevant les signaux réfléchis par les cibles.
Comparé à d'autres capteurs comme les caméras, LiDAR possède les caractéristiques suivantes :
Haute précision et résolution : LiDAR fournit des mesures de distance et d'angle de haute précision, générant des nuages de points haute résolution.
Forte adaptabilité : LiDAR peut fonctionner dans diverses conditions, y compris le jour, la nuit, la pluie et le brouillard, sans être limité par les conditions d'éclairage. Selon la conception et la fonction, LiDAR peut être utilisé dans un large éventail d'applications, de la détection atmosphérique à la conduite autonome.
Intégration et fiabilité : LiDAR à état solide est plus facile à intégrer dans les systèmes, réduisant l'usure mécanique et améliorant la fiabilité.
Coût et progrès technologique : Les coûts de LiDAR sont relativement élevés, et le niveau de maturité technologique varie, allant de systèmes mécaniques multi-lignes coûteux à des solutions à état solide plus économiques.
Importance des données LiDAR dans divers secteurs
Avec sa haute résolution, sa performance en temps réel et sa précision, les données LiDAR sont devenues un élément clé dans l'avancement technologique moderne et la transformation intelligente des industries.
Dans le domaine de l'automobile, LiDAR fournit une cartographie environnementale 3D de haute précision, permettant aux véhicules de percevoir en temps réel les obstacles environnants et d'assurer une navigation sûre.

Semblable à la technologie de conduite autonome, LiDAR dote les robots de capacités précises d'évitement d'obstacles et de positionnement dans le domaine de la robotique. Tant les robots de service en intérieur que les robots de manutention dans l'automatisation industrielle s'appuient sur LiDAR pour un fonctionnement efficace.
Même les industries traditionnelles comme l'agriculture subissent une transformation intelligente. Dans l'agriculture de précision, les données LiDAR sont utilisées pour surveiller la hauteur des cultures, analyser le terrain et optimiser les chemins de semis et de fertilisation pour améliorer l'efficacité de production. Intéressé à en savoir plus, découvrez 10 autres applications amusantes de LiDAR.
Acquisition et formats de données des nuages de points LiDAR
Les données LiDAR sont présentées sous la forme de nuages de points 3D. Un nuage de points est une collection de nombreux points 3D discrets, chacun contenant des coordonnées (X, Y, Z) et parfois des attributs supplémentaires tels que l'intensité de réflexion et la couleur.
En prenant comme exemple la technologie de Temps de Vol (ToF), l'obtention de données de nuages de points LiDAR nécessite d'abord que le système LiDAR émette des impulsions laser vers la cible. Ces impulsions sont réfléchies lorsqu'elles rencontrent des objets. Le récepteur dans le système capture ces impulsions lumineuses réfléchies et enregistre la différence de temps, c'est-à-dire le temps de trajet aller-retour des impulsions lumineuses. La distance à la cible est calculée en utilisant la vitesse de la lumière et le temps de trajet aller-retour. En combinant cela avec les informations sur l'angle de numérisation, les coordonnées 3D de chaque point sont déterminées.
Les formats courants de données de nuages de points incluent :
PCD (Point Cloud Data) : Fourni par PCL (Point Cloud Library), adapté à la vision par ordinateur et à la robotique, flexible et prenant en charge diverses structures de données.
LAS/LAZ : Développé par la ASPRS (American Society for Photogrammetry and Remote Sensing), un format de stockage standard pour les données de nuages de points, largement utilisé dans les systèmes d'information géographique (SIG). LAZ est une version compressée de LAS, économisant de l'espace de stockage.
PTS/PTX : Formats simples pour le stockage des données de nuages de points, contenant généralement des coordonnées XYZ et parfois des informations de couleur RVB.
ASC/XYZ : Formats texte, simples et directs, avec des données pour chaque point organisées par coordonnées XYZ, parfois y compris des informations supplémentaires telles que l'intensité ou la couleur.
Algorithmes essentiels de nuages de points
Traiter efficacement et avec précision les données des nuages de points est la clé pour mettre en œuvre des applications comme la conduite autonome et la navigation des robots.
Cette section introduira les algorithmes de base pour le traitement des nuages de points, y compris le prétraitement des nuages de points et les applications finales.
Prétraitement des nuages de points
Le prétraitement des données de nuages de points est une étape critique qui affecte directement la précision et l'efficacité des analyses et des applications ultérieures. L'objectif est de supprimer le bruit, de simplifier les structures de données et d'ajuster la position et l'orientation des nuages de points pour de meilleurs résultats.
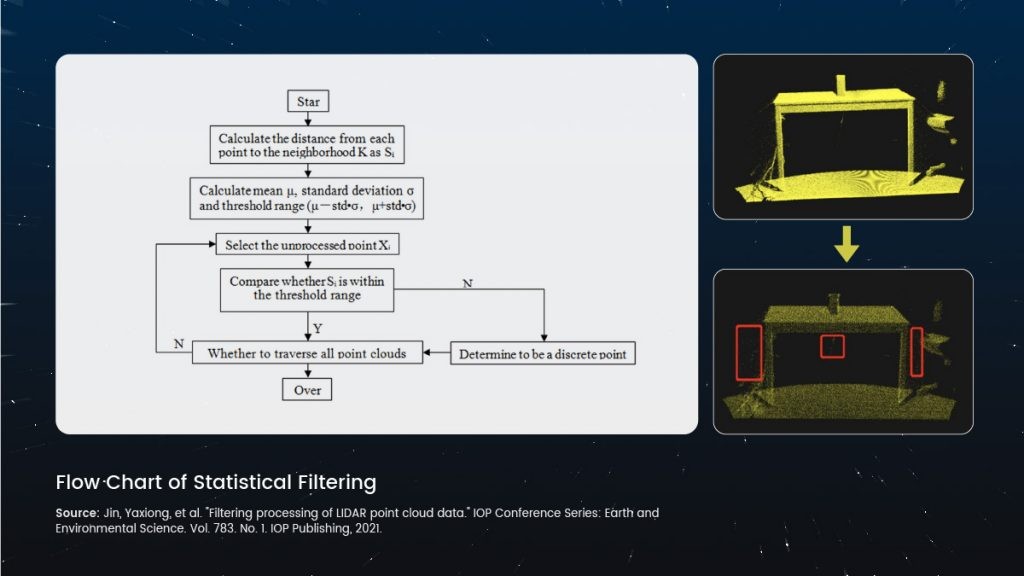
Les principales techniques de prétraitement incluent :
Débruitage des nuages de points
Le débruitage élimine les points bruyants causés par des erreurs de mesure, une interférence environnementale ou des limitations matérielles.
Le filtrage statistique est une méthode courante qui identifie et élimine les valeurs aberrantes en analysant la densité locale ou la distribution de distance des points, en supposant que les points bruyants sont éloignés de leurs voisins, tandis que les points réels sont étroitement liés.
Filtrage par rayon, tel que remove_radius_outlier dans Open3D, détermine et élimine les points bruyants en fonction du nombre de points à l'intérieur d'un rayon fixe de chaque point, en supposant que les points réels ont plus de voisins que les points bruyants.
Sous-échantillonnage des nuages de points
Le sous-échantillonnage réduit la quantité de données de nuages de points et améliore la vitesse de traitement tout en préservant les caractéristiques géométriques du nuage de points.
Le sous-échantillonnage par voxels est une technique courante qui divise l'espace en voxels (pixels 3D) et regroupe les points à l'intérieur de chaque voxel en un point représentatif, généralement le point central ou le centroïde. La fonction voxel_down_sample dans Open3D utilise ce principe, réduisant le nombre de points et simplifiant la structure des données sur la base de la taille du voxel.
D'autres méthodes simples et efficaces incluent le sous-échantillonnage uniforme et aléatoire.
Transformation des coordonnées
La transformation des coordonnées ajuste la position et l'orientation des nuages de points, y compris la translation et la rotation.
Les systèmes de coordonnées courants incluent les systèmes de coordonnées mondiales, de capteurs et d'objets. La transformation est réalisée à l'aide de matrices de rotation (angles d'Euler ou quaternions) et de vecteurs de translation, qui décrivent la rotation relative et le déplacement entre les systèmes de coordonnées.
En combinant la matrice de rotation et le vecteur de translation, on crée une matrice de transformation pour convertir le nuage de points d'un système de coordonnées à un autre, ce qui est crucial pour aligner les nuages de points de différentes perspectives et faire correspondre ou intégrer des données multi-sources.
Classification et détection des nuages de points
Après le prétraitement, les données des nuages de points peuvent être utilisées pour construire des données d'entraînement pour diverses applications de haut niveau, telles que la classification et la détection d'objets, qui identifient différents objets ou caractéristiques dans le nuage de points.
Méthodes d'apprentissage supervisé
L'apprentissage supervisé dans la classification des nuages de points combine l'ingénierie des caractéristiques et des algorithmes d'apprentissage automatique traditionnel.
Des caractéristiques telles que les normales de surface, la densité locale et les statistiques de distance sont extraites du nuage de points et utilisées comme entrée pour l'entraînement et la classification à travers des algorithmes comme Support Vector Machines (SVM), Random Forests, et K-Nearest Neighbors (KNN).
Cette méthode repose sur des caractéristiques conçues manuellement, et sa performance est limitée par l'efficacité et la généralité des caractéristiques.
Par exemple, l'histogramme des gradients orientés (HOG) ou les histogrammes de caractéristiques à points rapides (FPFH) peuvent être utilisés comme caractéristiques, puis entraînés à l'aide de classificateurs pour distinguer différentes catégories de nuages de points.
Méthodes d'apprentissage profond
L'apprentissage profond, en particulier les réseaux de neurones convolutionnels (CNN) et les réseaux spécifiques aux nuages de points comme PointNet, PointNet++, et Dynamic Graph CNN (DGCNN), ont fait d'énormes progrès dans la classification et la détection des nuages de points. Ces méthodes traitent directement les données de nuages de points brutes sans ingénierie manuelle des caractéristiques.
Pour la détection des nuages de points, des méthodes telles que Multi-View PointNet (MVP) et Votenet localisent et identifient des objets grâce à une fusion multi-vues ou un vote direct sur les nuages de points, ce qui est particulièrement important dans la conduite autonome et l'inspection industrielle.
Les méthodes d'apprentissage profond peuvent automatiquement apprendre des caractéristiques et gérer des structures de nuages de points complexes et variées mais nécessitent une grande quantité de données annotées pour l'entraînement.
Secteur des nuages de points
La segmentation des nuages de points divise les données des nuages de points en sous-ensembles ayant les mêmes attributs ou caractéristiques, aidant à comprendre la structure de la scène et à extraire des objets spécifiques.

Élargissement régional
L'élargissement régional est une méthode de segmentation basée sur des relations d'adjacence.
Elle part de points de départ et s'étend progressivement aux points voisins répondant à des critères de similarité spécifiques, tels que la distance ou la différence de caractéristiques. Lorsqu'un point nouvellement ajouté est suffisamment proche des caractéristiques de la région actuelle, il est fusionné dans cette région.
Cette méthode est simple et intuitive, mais le choix des conditions de croissance appropriées et des points de départ initiaux affecte considérablement les résultats, et elle est facilement influencée par le bruit.
Regroupement
Le regroupement des nuages de points regroupe les données des nuages de points en clusters, chaque cluster représentant une région d'objet ou de caractéristique possible.
Les algorithmes de regroupement courants incluent le clustering spatial basé sur la densité des applications avec bruit (DBSCAN), la moyenne de déplacement (Mean Shift) et le regroupement spectral.
DBSCAN est basé sur la densité des points et peut découvrir automatiquement des clusters de formes arbitraires, tandis que la moyenne de déplacement trouve des régions à haute densité de points de données par un processus itératif.
Ces algorithmes de regroupement peuvent gérer efficacement le bruit et les distributions irrégulières dans les nuages de points et sont des techniques très pratiques dans la segmentation des nuages de points.
Tout comme dans la classification et la détection, la segmentation des nuages de points nécessite également une grande quantité de données annotées pour l'entraînement et l'évaluation des algorithmes.
À propos de l'auteur
Admon Wang est un instructeur académique chez BasicAI, se concentrant sur les dernières tendances en IA, l'annotation de données et l'apprentissage automatique. Passionné par la vulgarisation des concepts complexes de l'IA, Admon collabore avec l'équipe d'ingénierie de BasicAI pour partager leurs innovations avec un public plus large. Il travaille également en étroite collaboration avec les clients de BasicAI, les aidant à tirer le meilleur parti des services et des produits de l'entreprise.
Articles récents

Sommet de l'IA générative 2024
Sommet de l'IA générative 2024

Étude de cas client : Comptabilité automatisée pour un traitement intelligent
Étude de cas client : Comptabilité automatisée pour un traitement intelligent

Étude de cas client : contrôle logistique IA
Étude de cas client : contrôle logistique IA

Étude de cas client : Filtre de requête pour une plateforme CRM
Étude de cas client : Filtre de requête pour une plateforme CRM

Étude de cas client : Classification des produits
Étude de cas client : Classification des produits

Étude de cas client : Interius Farms révolutionne l'agriculture verticale avec l'IA et la robotique
Étude de cas client : Interius Farms révolutionne l'agriculture verticale avec l'IA et la robotique

Étude de cas client : Essayage virtuel de vêtements
Étude de cas client : Essayage virtuel de vêtements

Étude de cas client : SURGAR proposant une réalité augmentée pour la chirurgie laparoscopique
Étude de cas client : SURGAR proposant une réalité augmentée pour la chirurgie laparoscopique

Étude de cas client : Gestion intelligente des drones
Étude de cas client : Gestion intelligente des drones

Étude de cas client : Correspondance des éléments de requête pour la gestion de base de données
Étude de cas client : Correspondance des éléments de requête pour la gestion de base de données